

第8回 画像認識

前回はAIで手話を解析してコミュニケーションを広げる研究について紹介しました。その中であげた「画像認識」の入口について話しをします。
「画像認識」とは画像内にどんな人や物があるかを認知する技術になります。例えば、りんごの写真を画像認識すれば、「なし」ではなく「りんご」と答えを出してくれることです。もっと言えば、「この位置」にりんごがある、と場所の指定までしてくれます。
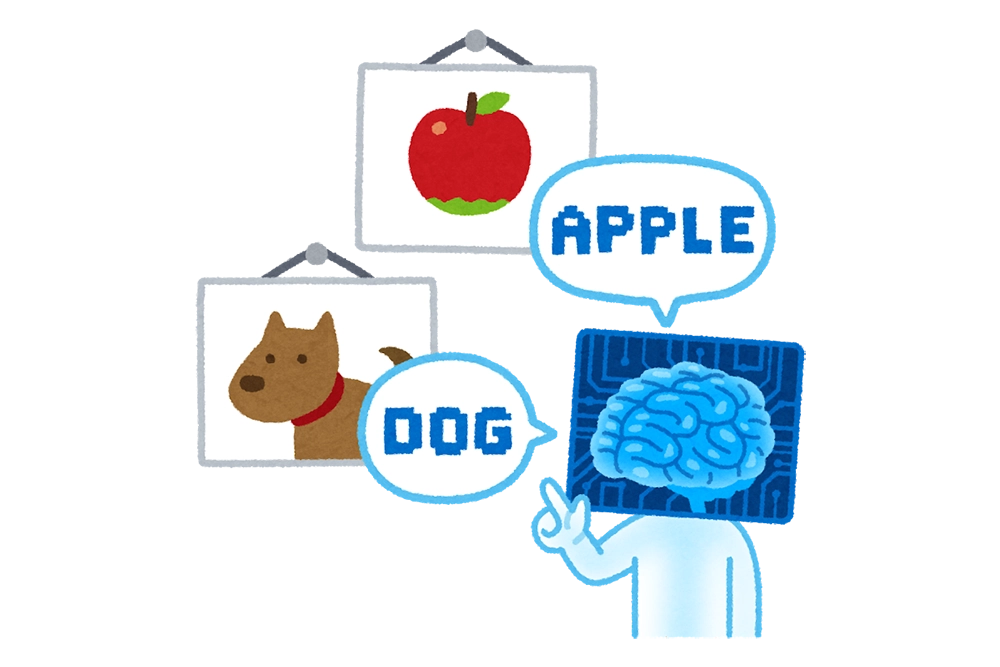
では、画像認識に深層学習が活用されるようになった背景を見てみましょう。
2005年にPASCAL VOC※1という大会が開催され2012年まで続きました。2012年はデータ数1万件を使用して、20のカテゴリーに分類するという大会でした。しかしこのカテゴリー数は少ないからもっと多くを分けられる大会を、ということで2010年にILSVRC※2が開催されました。この大会の中で深層学習を使用したモデルが圧倒的な精度をだすようになり、深層学習の人気が高まりました。この圧倒的なモデルは2012年にAlexNet(アレックスネット)として登場しました。そのときまでエラー率は約2%ずつしか改良されないと予想されていたものが、一気に10%近く改良されエラー率約16%になり、同年の他の参加者を驚かせました。モデルは8層からなるニューラルネットワークでした。以後、2014年にGoogleがエラー率約7%のGoogleNetで優勝しました。GoogleNetは22層からなるニューラルネットワークでした。2015年にはエラー率約3.6%のResNet(レズネット)が登場し、人間の認識率を優に超えました。ResNetは152層のニューラルネットワークでした。2017年の大会ではエラー率が約2.3%となり、ResNetと比べて約30%の改良になりました。これらのモデルの一部は一般的に公開されており、私たちも学習済みモデルとして利用することが可能です。
これらの技術により画像内に「何が」あるかを高い確率で予想することができるようになりました。
次回は画像内の「どこに」の技術について話をしようと思います。
[※1] PASCAL VOC:PASCAL Visual Object Classes Challenge
[※2] ILSVRC:ImageNet Large Scale Visual Recognition Challenge
「YSeye19号」掲載